|
FQL v4 will be decommissioned on June 30, 2025. Ensure that you complete your migration from FQL v4 to FQL v10 by that date. For more details, review the migration guide. Contact support@fauna.com with any questions. |
Getting started with Fauna and Cloudflare Workers
Introduction
In this guide, we’re going to build a simple CRUD API to manage a catalog inventory. The code will be deployed worldwide on Cloudflare’s infrastructure and executed on the serverless Workers runtime, with Fauna as the data layer. Both services share the same serverless global DNA. When combined, they are an ideal platform to build low-latency services that can handle any workload with ease.
Prerequisites
-
A Fauna account. Sign up or log in via the Fauna Dashboard.
-
Node.js (any recent version).
-
Cloudflare’s Wrangler CLI.
Why use Fauna with Cloudflare Workers?
Thanks to its nonpersistent connection model based on HTTP, Fauna integrates seamlessly with Workers. Applications using both services can run serverless end to end and be infinitely scalable with no need to manage infrastructure. This setup is ideal for low-latency services.
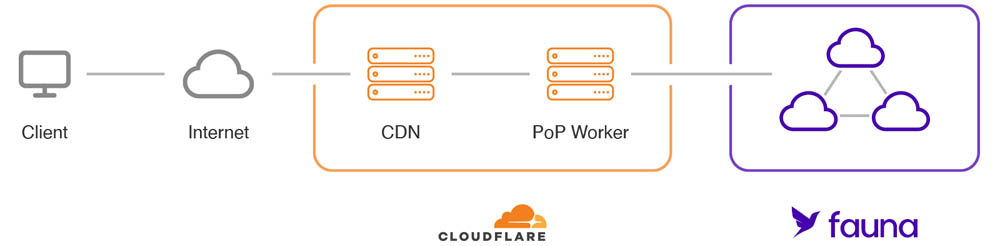
Typically, server-side applications run their business logic and database operations on single central servers. By contrast, an application using Workers with Fauna runs in globally distributed locations and the round trip read latency is greatly reduced.
If you’d like to talk to a Fauna expert about using Cloudflare Workers with Fauna, please contact us. Otherwise, read on to dive into a hands-on exercise!
What we’re building
Our application consists of a JavaScript REST API with CRUD capabilities that manages a simple product inventory.
Fauna is a document-based database. Our product documents include the following data:
-
title: a human-friendly string representing the name of a product. -
serialNumber: a machine-friendly string that identifies the product. -
weightLbs: a floating point number with the weight in pounds of the product. -
quantity: an integer number specifying how many of a product there are in the inventory.
The documents are stored in the Products
collection. For simplicity’s
sake, the endpoints of our API are public. Check some suggestions at the
end of the guide on how to improve this.
Finally, we’ll use Cloudflare Workers to execute the JavaScript code of our application at the edge.
Set up Fauna
-
Create a new database
-
In the Fauna Dashboard, click the CREATE DATABASE link in the upper left corner.
-
Name your database Cloudflare_Workers_Demo.
-
In the
Region Groupdropdown menu, select your Region Group. -
Leave the
Use demo databox unchecked. -
Click the CREATE button.
-
-
Create a new collection
-
Click the NEW COLLECTION button.
-
Name your collection Products.
-
Click the SAVE button.
-
-
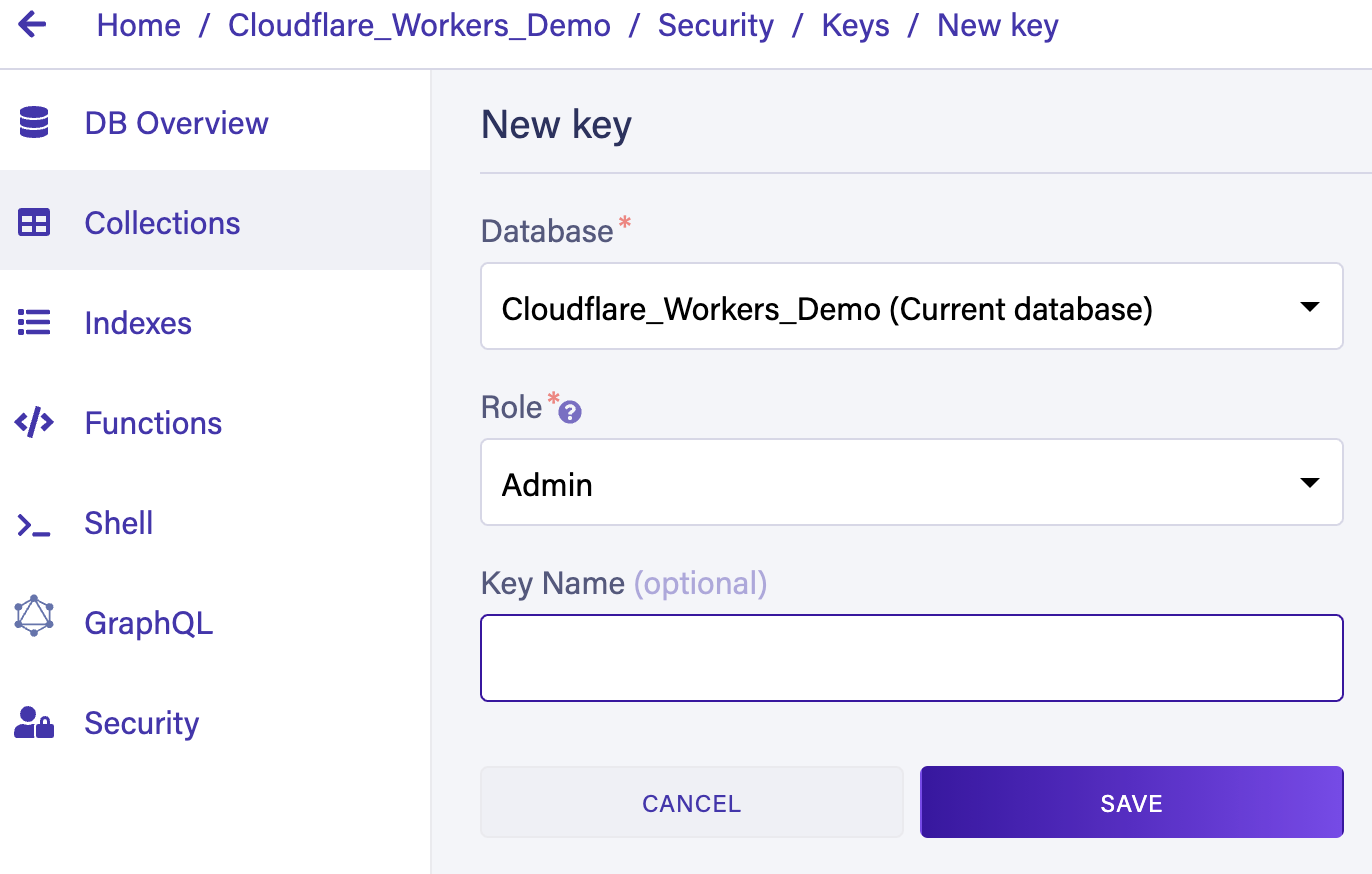
Create a new API key
-
Click SECURITY in the left-side navigation.
-
Click the NEW KEY button.
-
Select
Serverfrom theRoledropdown menu. -
Click the SAVE button.
-
Your key’s secret is displayed. Copy it and save it for later use. Be careful with your secret, and never commit it to a Git repository. Secrets are only ever displayed once. If you lose a secret, you must create a new key.
-
Your Fauna database is now ready to use.
Managing our inventory with Cloudflare Workers
-
Set up Cloudflare
If you haven’t already done so, create a Cloudflare account, enable Workers, and install the Wrangler CLI on your local development machine.
-
Configure Wrangler
-
Give Wrangler access to your Cloudflare account with the
logincommand:wrangler login -
Create a Workers project with the
generatecommand:wrangler generategeneratecreates a directory namedworkerwith several files, including one namedwrangler.tomlwhich looks similar to the following:name = "worker" type = "javascript" account_id = "" workers_dev = true route = "" zone_id = "" compatibility_date = "2021-11-23" -
Edit
wrangler.tomlto add your Cloudflare account ID. You can find your account ID and Workers subdomain on your Workers dashboard screen.
-
-
Create a test Worker
-
To test your Cloudflare configuration, create a test Worker. Your
workerdirectory contains all the necessary files. Publish your test Worker with the following terminal command:wrangler publishThis creates and uploads the Worker to Cloudflare. The command response should display your Worker’s web address.
Check your URL for a
Hello worker!message. If it’s there, your configuration is correct. If not, re-check your account ID and subdomain on your Workers dashboard screen.
-
-
Add your Fauna secret as an environment variable
Once the Worker has been created and deployed, you can store your Fauna secret as an environment variable on Cloudflare’s infrastructure. Use the following terminal command:
wrangler secret put FAUNA_SECRETAt the prompt, paste the Fauna key secret you created earlier.
It’s also possible to configure environment variables directly in the
wrangler.tomlfile, but that’s a bad idea if you plan to add it to a Git repository. -
Install dependencies
-
Install the Fauna JavaScript driver with the following terminal command:
npm install faunadb -
Install the Worktop framework for Cloudflare Workers:
npm install worktop@0.7Worktop provides basic functionality such as path parameters, query string parameters, and HTTP methods right out of the box.
-
-
JavaScript utility functions
Your CRUD API system needs a utility function for error handling. Create a file called
utils.jsin your project folder with the following content:export function getFaunaError(error) { const { code, description } = error.requestResult.responseContent.errors[0]; let status; switch (code) { case 'unauthorized': case 'authentication failed': status = 401; break; case 'permission denied': status = 403; break; case 'instance not found': status = 404; break; case 'instance not unique': case 'contended transaction': status = 409; break; default: status = 500; } return { code, description, status }; }The
getFaunaError()function extracts the code and description of the most common errors returned by Fauna. It also determines the HTTP status code for each error. -
Inventory logic
Replace the contents of your
index.jsfile with the skeleton of an API:import {Router, listen} from 'worktop'; import faunadb from 'faunadb'; import getFaunaError from './utils.js'; const router = new Router(); const faunaClient = new faunadb.Client({ secret: FAUNA_SECRET, domain: 'db.fauna.com', // NOTE: Use the correct domain for your database's Region Group. }); const q = faunadb.query; listen(router.run);Let’s take a closer look at the initialization of the Fauna client:
const faunaClient = new faunadb.Client({ secret: FAUNA_SECRET, domain: 'db.fauna.com', // NOTE: Use the correct domain for your database's Region Group. });The
FAUNA_SECRETenvironment variable is automatically injected into our application at runtime. Workers runs on a custom JavaScript runtime instead of Node.js, so there’s no need to useprocess.envto access these variables. The Fauna secret you uploaded belongs to a key with the Server role, which gives our Worker full access to your Fauna database. -
Add a POST API endpoint
The POST endpoint receives requests to add documents to your
Productscollection. Add the following lines to yourindex.jsfile:router.add('POST', '/products', async (request, response) => { try { const {serialNumber, title, weightLbs} = await request.body(); const result = await faunaClient.query( q.Create( q.Collection('Products'), { data: { serialNumber, title, weightLbs, quantity: 0 } } ) ); response.send(200, { productId: result.ref.id }); } catch (error) { const faunaError = getFaunaError(error); response.send(faunaError.status, faunaError); } });For simplicity’s sake, there’s no validation of the request input on these examples.
This route contains a JavaScript FQL query which creates a new document in the
Productscollection. If the query is successful, theidof the new document is returned in the response body.If Fauna returns an error, the client raises an exception, and the program catches that exception and responds with the result from the
getFaunaError()utility function. -
Add a GET API endpoint
The GET endpoint retrieves a single document in your
Productscollection by its ID. Add the following lines to yourindex.jsfile:router.add('GET', '/products/:productId', async (request, response) => { try { const productId = request.params.productId; const result = await faunaClient.query( q.Get(q.Ref(q.Collection('Products'), productId)) ); response.send(200, result); } catch (error) { const faunaError = getFaunaError(error); response.send(faunaError.status, faunaError); } });The FQL query uses the
Getfunction to retrieve a document from a document reference. If the document exists, it is returned in the response body. -
Add a DELETE API endpoint
The DELETE endpoint deletes a single document in your
Productscollection by its ID. Add the following lines to yourindex.jsfile:router.add('DELETE', '/products/:productId', async (request, response) => { try { const productId = request.params.productId; const result = await faunaClient.query( q.Delete(q.Ref(q.Collection('Products'), productId)) ); response.send(200, result); } catch (error) { const faunaError = getFaunaError(error); response.send(faunaError.status, faunaError); } });The FQL query uses the
Deletefunction to delete a document by its reference. If the delete operation is successful, the deleted document is returned in the response body. -
Add a PATCH API endpoint
The PATCH endpoint updates a single document in your
Productscollection by its ID. You’ll use it to manage your product inventory by reading and updating thequantityfield in your product documents.Keeping your product inventory up to date involves two database operations: reading the current quantity of an item, and then updating it to a new value. If you perform these two operations separately, you run the risk of getting out of sync, so it’s better to perform them as part of a single transaction.
Add the following lines to your
index.jsfile:router.add('PATCH', '/products/:productId/add-quantity', async (request, response) => { try { const productId = request.params.productId; const {quantity} = await request.body(); const result = await faunaClient.query( q.Let( { productRef: q.Ref(q.Collection('Products'), productId), productDocument: q.Get(q.Var('productRef')), currentQuantity: q.Select(['data', 'quantity'], q.Var('productDocument')) }, q.Update( q.Var('productRef'), { data: { quantity: q.Add( q.Var('currentQuantity'), quantity ) } } ) ) ); response.send(200, result); } catch (error) { const faunaError = getFaunaError(error); response.send(faunaError.status, faunaError); } });Let’s examine the FQL query in this route in more detail.
It uses the
Letfunction to establish some variables you’ll need later on:-
productRefis a document reference. -
productDocumentcontains the full product document, returned by theGetfunction. -
currentQuantitycontains the value from thequantityfield of the document. TheSelectfunction extracts thequantityfield from the specified document.After declaring the variables,
Letaccepts a second parameter which can be any FQL expression. This is where we you update the document:q.Update( q.Var('productRef'), { data: { quantity: q.Add( q.Var('currentQuantity'), quantity ) } } )The
Updatefunction only updates the specified fields of a document. In this example, only thequantityfield is updated. The new value ofquantityis calculated with theAddfunction.It’s important to note that even if multiple Workers are updating product quantities from different geographical locations, Fauna guarantees the consistency of the data across all Fauna regions.
Now you have API routes to create, delete, retrieve, and update documents. You can now publish your Worker and try it out.
-
-
Publish your Worker
Publish your Worker with the following terminal command:
wrangler publish -
Try it out
Create a new product document with the following terminal command. Replace
<worker-address>with the HTTPS address of your Workers account, which you can find on your Workers dashboard. It should look something likecloudflare.my-subdomain.workers.dev.curl \ --data '{"serialNumber": "H56N33834", "title": "Bluetooth Headphones", "weightLbs": 0.5}' \ --header 'Content-Type: application/json' \ --request POST \ https://<worker-address>/productsIf the request is successful, you should get a response body which contains the product ID of your new document:
{"productId":"315195527768572482"}You can go to your Fauna Dashboard and look at your
Productscollection to see the new document. You can also send aGETrequest to retrieve the new document. Replace<worker-addressand<document-id>with the correct values:$ curl \ --header 'Content-Type: application/json' \ --request GET \ https://<worker-address>/products/<document_id>Next, let’s use the
PATCHendpoint to update thequantityfield of the document.$ curl \ --data '{"quantity": 5}' \ --header 'Content-Type: application/json' \ --request PATCH \ https://<worker-address>/products/<document_id>/add-quantityThe above terminal command should return the complete product document with an updated
quantityfield. The terminal output isn’t formatted for easy reading, but you can always return the Fauna Dashboard and look at your document there.Finally, let’s use the
DELETEendpoint to delete the document.$ curl \ --header 'Content-Type: application/json' \ --request DELETE \ https://<worker-address>/products/<document_id>
Further improvements to the application
Your inventory application has been kept very simple for demonstration purposes, but it lacks essential features.
For example, all endpoints of the API are public. A real-world application makes use of authentication and authorization to maintain security. Here are some resources for learning about application security with Fauna.
Is this article helpful?
Tell Fauna how the article can be improved:
Visit Fauna's forums
or email docs@fauna.com
Thank you for your feedback!